Cortex
Cloud ML infrastructure at scale
ML Ops
Deploy, manage, and scale machine learning models in production.
8.0kstars598forks23contributors114issuesLast commit 3y ago
READ MORE ABOUT CORTEX
Cortex provides cloud infrastructure for deploying, managing, and scaling machine learning models in production. It supports various workloads, including real-time, asynchronous, and batch processing, with automated cluster management and CI/CD integrations for seamless operation.
•Serverless workloads: Respond to requests in real-time and autoscale based on in-flight request volumes.
•Async processing: Handle requests asynchronously and autoscale based on request queue length.
•Batch processing: Execute distributed and fault-tolerant batch processing jobs on-demand.
•Cluster autoscaling: Scale clusters elastically with CPU and GPU instances.
•Spot instances: Run workloads on spot instances with automated on-demand backups.
•Environments: Create multiple clusters with different configurations.
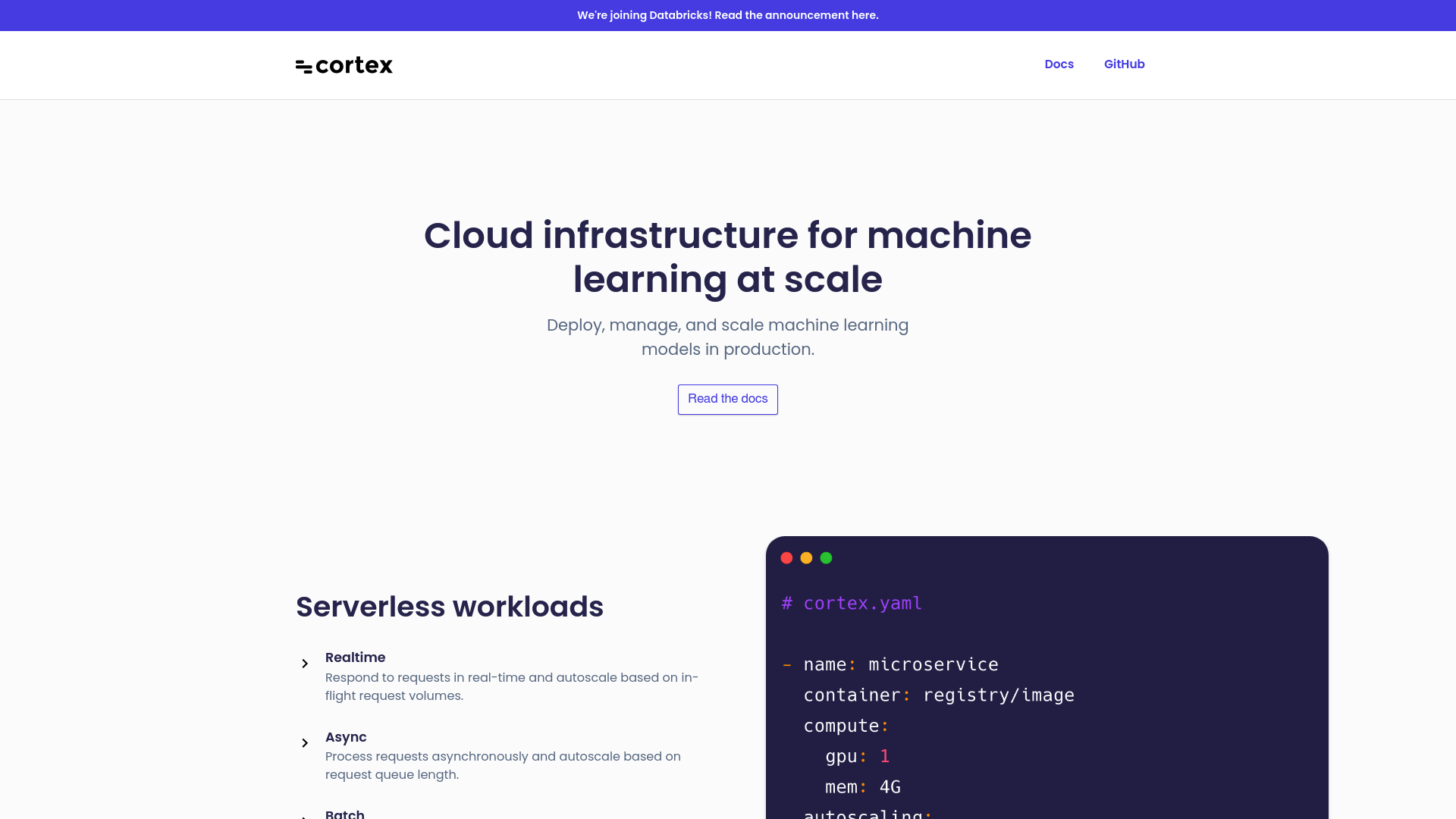
•Provisioning: Provision clusters with declarative configuration or a Terraform provider.
•Metrics: Send metrics to any monitoring tool or use pre-built Grafana dashboards.
•Logs: Stream logs to any log management tool or use the pre-built CloudWatch integration.
•EKS: Cortex runs on top of EKS to scale workloads reliably and cost-effectively.
•VPC: Deploy clusters into a VPC on your AWS account to keep your data private.
•IAM: Integrate with IAM for authentication and authorization workflows.
•Model serving: Deploy machine learning models as real-time workloads and scale inference across CPU or GPU instances.
•MLOps: Create services that continuously retrain and evaluate models to maintain their accuracy over time.
•Microservices: Scale compute-intensive microservices without dealing with timeouts or resource limits.
•Image, video, and audio processing: Scale data processing pipelines to handle large structured or unstructured data sets.
Cortex is built for AWS, leveraging EKS, VPC, and IAM to ensure reliable, secure, and scalable machine learning applications. Its comprehensive feature set makes it an invaluable tool for managing machine learning operations at scale.